- Bionic Marketing
- Posts
- Issue #35: AI’s human touch, Claude 3, and conversational search
Issue #35: AI’s human touch, Claude 3, and conversational search
Sam Woods
March 11, 2024

Good morning.The LLM race continues.
Last week, we talked about Le Chat vying for the dominant spot above Chat GPT.
This week, we’re talking about Claude 3 (Anthropic) entering the race as the newest challenger to ChatGPT’s crown.
What does it all boil down to?
It’s a race of inches.
All to see which chatbots can make incremental progress above the others in key benchmarks.
More on benchmarks below.
—Sam
IN TODAY’S ISSUE 👨🚀

Claude 3: Emotional intelligence in the battle for LLM supremacy
“Beam me up Scotty” – the surprisingly nerdy behavior that stumped AI researchers
Perplexity AI makes strides in conversational search
Let’s dive in.

Chasing benchmarks vs. enhancing workflows: the marketer’s dilemma in the age of AI
Anthropic claims that Claude 3 sets “new industry benchmarks across a wide range of cognitive tasks”.
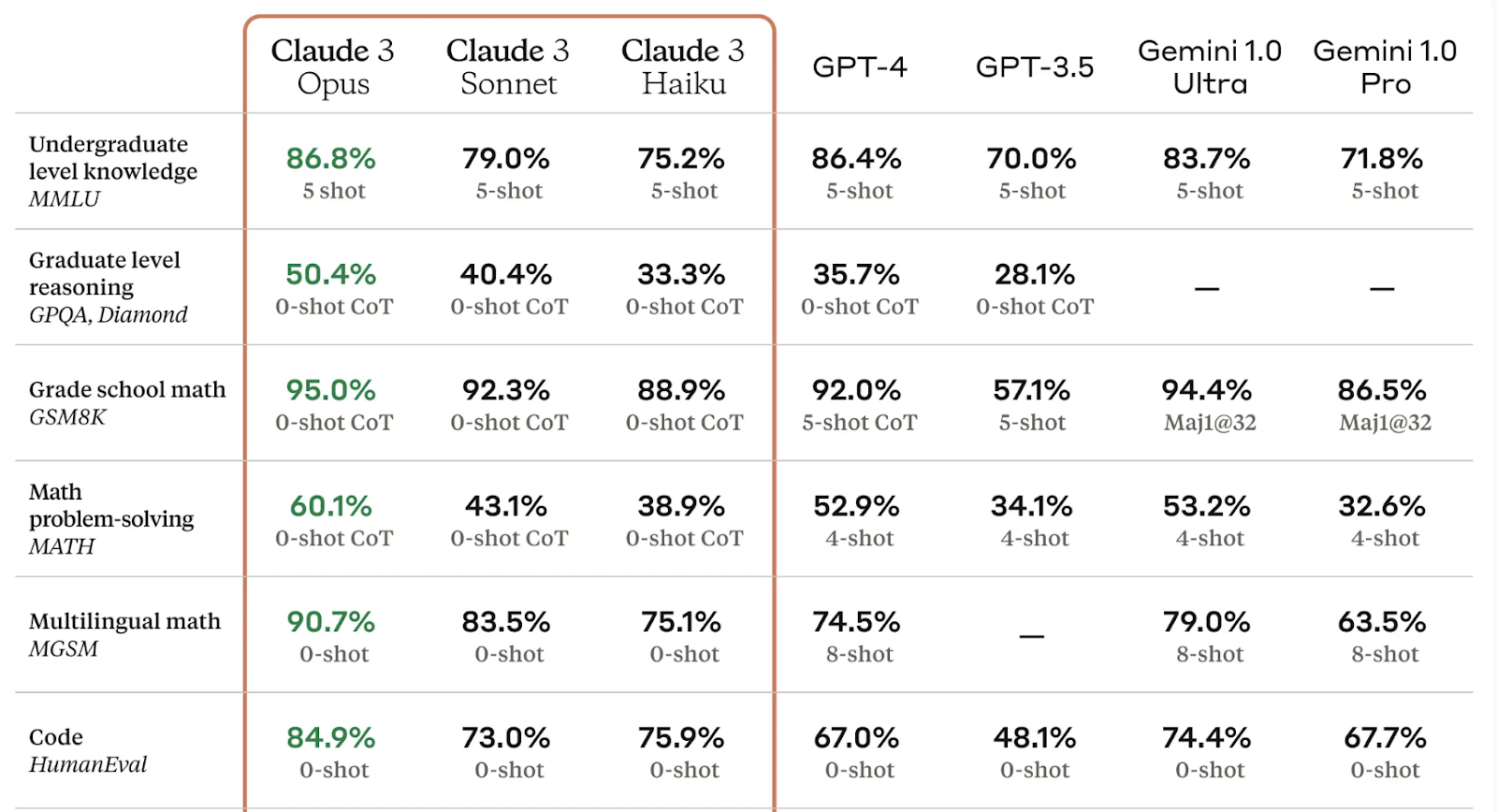
Claude 3 brings three new models of chatbots. All with different use-cases and applications depending on your needs.
Haiku: Best if you’re looking for speed and affordability above overall performance. The most limited of the three models, it answers simple queries and requests.
Sonnet: Strikes the balance between cognitive ability and speed. Could be well-suited for large-scale enterprise functions.
Opus: Touts high levels of performance and processing power across multiple domains. This premium model is where Claude wins some ground against key benchmarks among competitors.
The biggest claim from Claude 3 is that “it exhibits near-human level of comprehension and fluency on complex tasks, leading the frontier of general intelligence”.
An LLM that operates with human-like comprehension?
AGI (Artificial General Intelligence) is what they’re referring to, and it’s the holy grail of AI capability.
Claude is yet another platform claiming to have achieved AGI, much like OpenAI did with Q*.
Imagine how AI could be leveraged if a platform like Claude 3 could accomplish these tasks quickly?
For the cost of a $20 monthly subscription?
We’re not there yet, but I have no doubts that we will be, probably faster than we think.
But let’s bring this back to practical application.
To the average marketer, it’s mind-numbing to try and keep pace with the latest roll-outs.
As I said earlier, the LLM race is one of inches at this point.
All of them are vying for the top spot, all of them touting the latest breakthrough based on incremental improvements over others.
Most of this is just chatter.
What marketers are really looking for is technology that is intuitive.
That feels more human.
Why?
It makes prompting less complicated
Intuitive AI makes collaboration easier, and more enjoyable
It enhances creativity
Many claim that Claude 3 is the most human chatbot they’ve encountered so far:
Ryan Morrison of Tom’s Guide tested the limits of Claude’s emotional IQ and came up with some interesting results.
Also worth reading is this article from Every that called Claude “warm”.
My advice to you?
Find the solutions that feel the easiest to use, AND that give you the highest quality outputs for the use case you need them for.
Then, keep your head down and focus on getting really good with these models.
Build custom GPTs on these platforms, optimize them for maximum efficiency with your workflows, and put them through their paces.
Save the “next big thing” for experimenting and playing around with.
What marketers are really wondering when they see major rollouts like this:
“Can I access a cheaper model with roughly the same capabilities as ChatGPT?”
Or:
“Can I pay a premium to access a technology that slightly outperforms GPT in some key benchmarks that are important to me?”
The answer:
It all depends on your use case, but it seems that Claude 3 could be a strong contender for all things branding and content creation.
Here’s the scoop straight from Anthropic:

Right now, Haiku and Sonnet are free, and as with other models I encourage you to give them a try.
Mess around with them, ask them everything from the outlandish to the practical and see what kind of output you get.
And speaking of the outlandish and unusual…
A new study found that AI performed better when prompted to answer as a Star Trek captain
Apparently the secret for making LLM’s master basic arithmetic has something to do with pretending to be Jean-Luc Picard?
It’s no joke.
A new study performed by NLP lab VMware found that prompting AI assistants to answer math problems while acting as a Stark Trek captain significantly boosts their calculation accuracy.
Math has always been the Kobayashi Maru scenario for chatbots and language models.
AI assistants are trained to mine massive data troves, and then randomly spit out whichever words or numbers have the highest probability of producing a “satisfactory” response.
This approach works like a charm when you need the model to crank out some halfway decent sentences, or analyze the plot of 1984.
Start hitting them with straightforward scenarios where there’s exactly one correct solution and that’s where things fall apart.
Crunching definitive arithmetic answers simply isn’t in most language models’ core programming.
We’ve known for a while now that chatbots perform better with a little positive reinforcement.
Previous research from DeepMind has shown us that LLM’s yield more accurate results with nudging from conversational prompts like:
“Let’s think step by step”
“Take a deep breath”
“C’mon, you can do better than that!”
But the real head-scratcher for researchers is that they can’t logically explain why the Trekkie trick works so effectively.
Their best guess is that the language models’ training data happened to contain some stellar examples of Starfleet officers rattling off flawless calculations amid tense space battles.
But it’s just speculation.
Researchers are stumped:

Either way, the unexpected findings of this study makes one thing crystal clear – language models are amazing tools, but they’re also inscrutable black boxes full of surprising quirks.
As Doug Heaven points out in his insightful article:

I don’t know about you, but I find the whole thing utterly fascinating.
Advanced AI, representing humanity's greatest apex of machine reasoning (right now), behaving in unpredictable, quirky, and downright silly ways.
It all sounds oddly — human. Doesn’t it?
As it turns out, chatbots are also getting “more human” when it comes to search as well
And this is a huge win for AI-assisted search.
Startup Perplexity AI has set its sights on taking some market share from Google, and it might just have unlocked the key to pulling it off.
Their secret weapons?
RAG keeps the bot grounded in reality by fetching relevant data from a constantly-updated database before it generates a response.
PerplexityBot: their adorably named web crawler that indexes the internet regularly. The bot makes the most out of limited resources by prioritizing sites by “domains”. News sites are updated every hour, while static pages might only update every few days.
Leverages Google's BERT model to enhance webpage understanding and ranking, enabling competitive search results despite limited resources.
The result?
Instead of just ranking pages and hoping the right answer is at the top, Perplexity AI actually reads and analyzes the info from its curated index to generate the most relevant answer.
Imagine this: you’re a content strategist tasked with creating a comprehensive guide on influencer marketing for your company’s blog.
You start by googling terms like “influencer marketing strategy” or “how to work with influencers”.
You then spend your time combing through countless articles, trying to separate the signal from the noise and piece together a coherent, up-to-date overview of best practices.
Or:
You could turn to Perplexity and say “Can you give me a rundown of key influencer marketing strategies, platforms, and metrics I should cover, along with some examples of successful campaigns from the last year or two?”
And boom, the bot comes back with a neatly summarized answer, pulling from multiple reputable sources.
Which of those two interactions feels the most human, the most conversational?
The real magic of a solution like this is in the back-and-forth as you interact with it like a search companion.
As you review the output, you might realize you need more detail on a particular topic, let’s say “navigating FTC guidelines for sponsored content”, so you ask the chatbot to elaborate.
And it happily obliges, providing a concise summary of key regulations and best practices for staying compliant.
There’s something so uniquely human (and satisfying) about having questions answered directly without parsing through irrelevant information.
It’s the difference between asking a seasoned librarian for help finding the best book on your subject vs. wandering aimlessly through the stacks reading through volumes of dribble.
Let’s address the elephant in the room:
Can’t Google, in all their infinite resources and wisdom mimic exactly what Perplexity is doing at an even grander scale?
The Perplexity team believes Google’s cash cow – search ads – could actually hold back from really innovating in this area.

From Picard-impersonating math whizzes to search engines that actually understand what you’re rambling about, AI is getting more human by the day.
These advancements are just the very beginning of even more intuitive, relatable, accurate AI assistants.

So, about benchmarks.
They’re cool and all.
They give researchers, and tech pundits something to compare, experiment, and test against.
But what are we really measuring with these metrics?
What are we striving towards?
Is AI getting closer to responding, reasoning, and navigating ambiguity the same way that a human could?
We’ve still got a ways to go – but we’re making strides.
ChatGPT, Mistral, Gemini, and Claude 3 may be locking horns in the LLM arena, but this signals good things for marketers.
Solutions are becoming cheaper, faster, and “more human” than they’ve ever been before.
Talk again soon,
Sam Woods
The Editor