- Bionic Marketing
- Posts
- Issue #33: End of video with Sora? Gemini from Google wins
Issue #33: End of video with Sora? Gemini from Google wins
Sam Woods
February 17, 2024

Good morning.
Everyone’s drooling over Sora, the new video model from OpenAI.
But I’m actually more excited about Gemini 1.5 Pro from Google.
Why?
Memory recall.
Let’s dive in.

BIONIC NEWS
People are freaking out over Sora, the new Text-to-Video Model from OpenAI.
(I believe Sora is “sky” in Japanese?)
I’ve been a heavy user of RunwayML, Pika, and other text-to-video tools for a while, so I wasn’t as floored as some were.
But I’m still very impressed.
Most impressive?
Footage of the gold rush in California:

There was no drone, let alone camera, around back then that could shoot this.
And to build a set like this, and film, costs a lot of money.
Watch this. It’s breathtaking.
But now?
You can have any scene (historical or whatever) generated that you can imagine.
If you’ve been a reader, what’s one thing I’ve kept repeating over and over again?
Imagination wins.
You need to get good at imagination—and articulating your imagination.
This goes beyond prompting. Prompts are only as good as how you can articulate your vision.
There are no “prompt tricks” that will last, if they work at all. Models are non-deterministic and probabilistic. You can’t get the same output every time.
You have to get good at formulating and articulating your imagination.
Sharpen your sense of taste, your perspective—is this starting to sound familiar?
Anyway, a summary for you:
Sora is a state-of-the-art text-to-video model developed by OpenAI. It’s not widely available yet, though some users have access (like myself).
Generates videos from text prompts, creating realistic and imaginative scenes.
Can produce videos up to a minute long with high visual quality.
Capable of generating complex scenes with multiple characters, specific motions, and accurate backgrounds.
Technical Highlights:
Builds on research from DALL·E and GPT models.
Uses a recaptioning technique from DALL·E 3 for better adherence to text prompts.
Multimodal capabilities: can animate still images or extend existing videos.
Deep understanding of language for generating compelling characters and emotions.
Capabilities:
Generates complex scenes with detailed characters and backgrounds.
Can create multiple shots within a single video, maintaining character consistency and visual style.
Limitations:
May struggle with simulating complex physics accurately.
Possible confusion in understanding specific cause and effect.
Spatial details (e.g., left and right) may be mixed up.
What does this all mean?
A few things:
Stock footage websites are probably irrelevant.
Anyone can have great B-roll, immediately. Makes life easy for editors.
Reduced or eliminate barriers to entry for high production value.
Businesses that rely on educational/explainer videos are in for an existential crisis.
Ad video creation is now 100x faster, easier, and cheaper.
VSL creation? The same.
Now that anyone and everyone can make amazing videos, what will matter?
The “big idea” and story.
Your angle and hooks.
Your taste and perspective.
But I repeat myself.
Anyway, here’s what I’m actually most excited about:

You should get familiar with Gemini 1.5 Pro, because this is big news for marketers and entrepreneurs.
Why?
Because the context window is not only HUGE—but it’s accurate.
Claude’s 100k window is great but falls apart when pushed to the limits (like pasting a whole sales page and asking for a rewrite—it can be done, it’s just not perfect).
But the Gemini context window?
Accurate across context length.
Recall is 100% up to about 500,000 tokens.
Trust me, you’ll probably never use more than that.
With a standard context window of 128,000 tokens, with an experimental feature allowing up to 1 million tokens (and successfully tested up to 10 million tokens in research).
This allows for processing extensive amounts of information, such as 1 hour of video, 11 hours of audio, or over 700,000 words in a single prompt.
You can now paste an entire VSL script or sales page—and do whatever you want with it. Including rewriting it for a different product and for a different audience.
(And it emulates the style, voice, etc.)
Get this:
“1.5 Pro can perform highly-sophisticated understanding and reasoning tasks for different modalities, including video. For instance, when given a 44-minute silent Buster Keaton movie, the model can accurately analyze various plot points and events, and even reason about small details in the movie that could easily be missed.”
And:
“Gemini 1.5 Pro also shows impressive “in-context learning” skills, meaning that it can learn a new skill from information given in a long prompt, without needing additional fine-tuning.”
Got a whole swipe file of a legendary copywriter?
Load it up, Scotty. Now we’re cooking, as the cool kids say these days.
It’s also multimodal, which means it can process text, images, videos, audio, and code.
Did you think the AI train would slow down in 2024?
Sweet, summer child.
Don’t get swept up in the hype, though. When everyone’s either hyping or panicking, you win if you can keep your head cool, clear eyes, full hearts—can’t lose.
You really should take a few minutes to either read the blog post or this X/Twitter thread.
It’s worth your time.
I’m most excited about this update because of the accurate, long context window. It’ll simplify a lot.
You can load a whole sales page now, and get a rewrite, but you have to do it in chunks, it’s error-prone, and takes time.
This? Easy peasy, lemon squeezy.
Finally, about memory… What if ChatGPT could remember things about you?
It would be bad news if it could recall every time you’ve promised to tip $200.
But, aside from that, OpenAI shared a new feature that they are still calling an "experiment for a small group of users."
The feature allows the chat to remember things about you from your conversations to personalize its responses.
How does it work?
Similar to Custom Instructions, which allows you to add permanent information about yourself and any other helpful context, the chat creates a profile for itself that consists of sentences it has understood about who you are and what your preferences are.
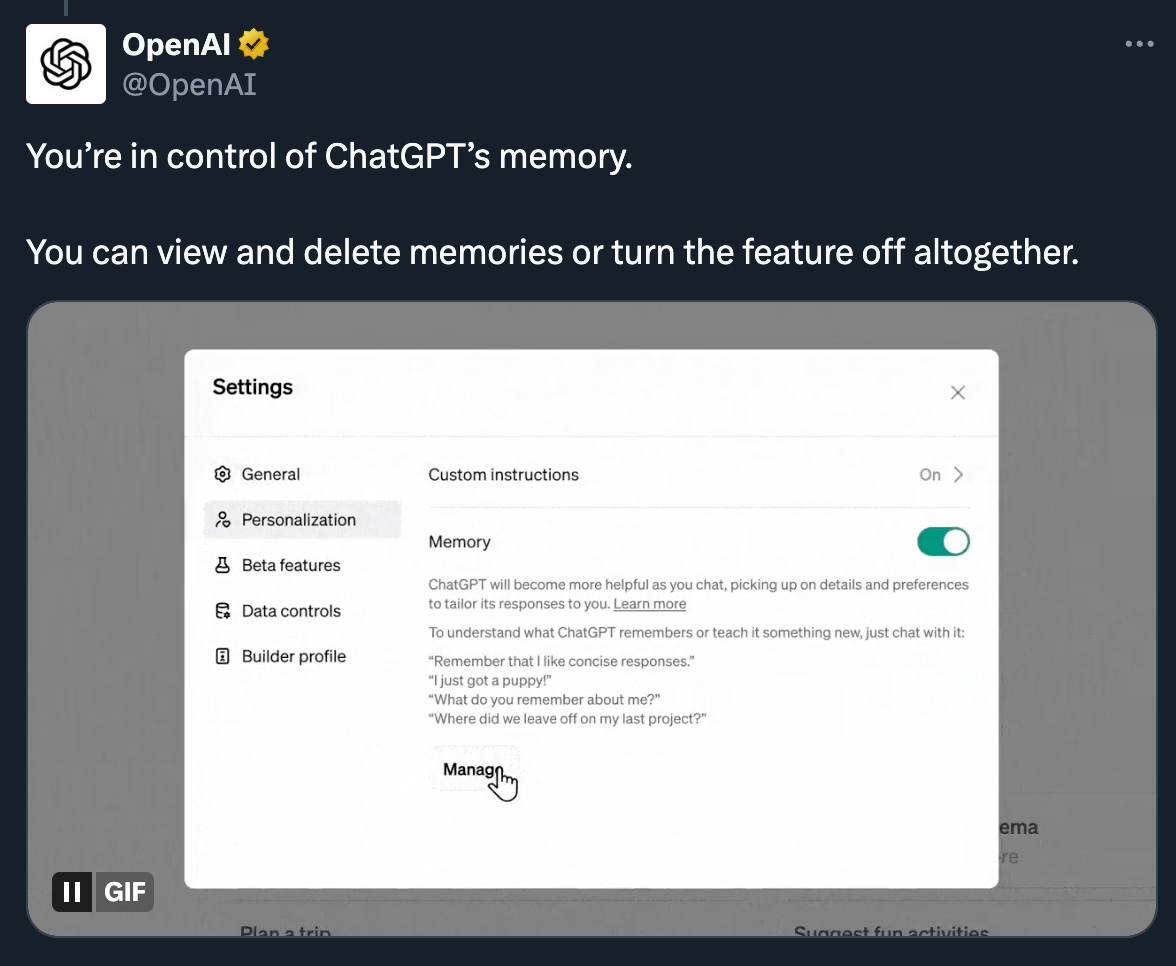
In the announcement video, they show sentences that the chat saved like "he likes to travel" or "wants to start a healthy diet soon" which is indeed useful information.
It’s like ChatGPT keeps a notepad, a “memory”, of certain things that can be easily called upon later, without you having to include it in a prompt.
It’s a decent update but with Custom GPTs, you can already have a custom version of ChatGPT that “knows” and “remembers” anything you want it to (either with Instructions or Knowledge Files).
BIONIC NEWS
I want you to pay attention to those two sentences of mine.
Just because we can do a lot (already!) with AI, does that mean we should?
No, it doesn’t.
We should not, for example, normalize facial recognition across everything we do, including at airports. It’s dehumanizing. Think about it: Only a machine can tell you if you’re you, and a human?
For now, facial recognition is optional at US airports at least. Opt out. You have the right to.
Just because we can use facial recognition doesn’t mean we should.
The same goes for any kind of AI and Machine Learning implementations, down to simple things like generating content.
What’s possible? Almost everything right now. Soon? Everything.
Just because you can, should you?
You have a choice.
Most people don’t realize they do.
But you do, right?
Talk again soon,
Sam Woods
The Editor